Perché i tool per identificare i testi scritti con AI non funzionano (e neppure il fact checking via AI)

Nelle nostre peregrinazioni online ci siamo imbattuti in un interessante esperimento: i tool per identificare i testi scritti con AI non funzionano, parola (ragionatissima) di Carlo Santagostino, informatico, imprenditore, scrittore, ispiratore di rubriche come Shadow’s Play e dell’amore per l’informatica che molti dei presenti hanno.

Perché i tool per identificare i testi scritti con AI non funzionano (e neppure il fact checking via AI)
E che l’ha dimostrato in un modo interessante: dando in pasto ai vari modelli di identificazione brani scelti della Costituzione Italiana.
Perché i tool per identificare i testi scritti con AI non funzionano (e neppure il fact checking via AI)
Abbiamo ripetuto l’esperimento: Smodin non ha dubbi, la Costituzione è opera di mano umana. Ma strumenti blasonati come ZeroGPT si sono platealmente offerti di darci una mano “riscrivendo la Costituzione” in modo gradevole al più “affidabile degli strumenti”.
Non ci siamo ovviamente piegati a questo sacrilegio, anche perché ovviamente ZeroGPT ci ha richiesto un obolo per sfoggiare la sua abilità rispetto ai nostri Padri Costituenti accusati di essere cyborg venuti dal futuro.
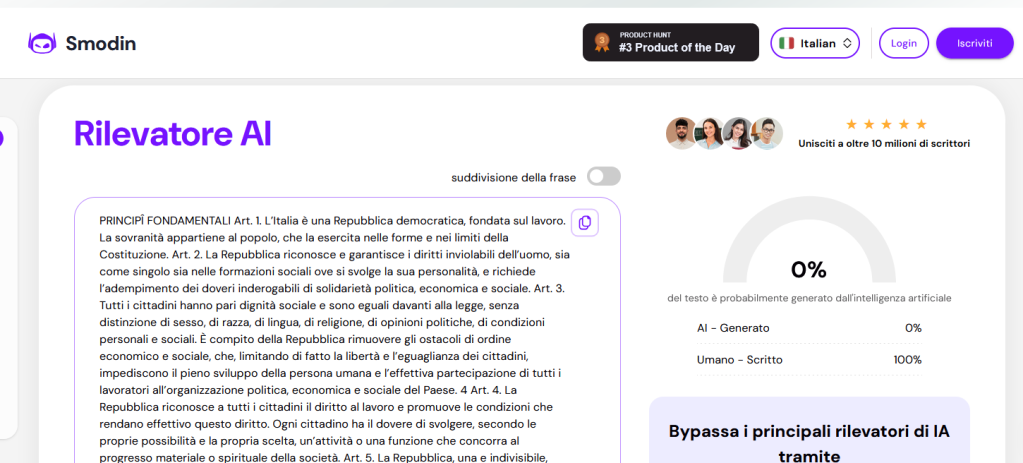
Smodin scagiona la Costituzione Italiana
Il buon Santagostino ha provveduto a fare il giro di diversi altri strumenti, e tranne Smodin, tutti quanti si sono prodotti nella stroncatura.
Ars Tecnica, pagina in lingua inglese aveva ripetuto questo esperimento concettuale, confermando che agli occhi dell’Intelligenza Artificiale, la Costituzione Americana e la Sacra Bibbia sono prodotti dell’intelligenza artificiale.
Cosa che ZeroGPT conferma, dichiarando che anche nell’edizione italiana la Bibbia è un prodotto della IA.

Ma ChatGPT la condanna
Escludendo che ChatGPT sia diventato il Signore nostro Dio Creatore del Cielo e della Terra, Ars Technica propone una spiegazione che l’esperto Santagostino conferma e vi riportiamo.
La spiegazione
Ritenere che le AI “pensino” e “ragionino” è un errore comune di cui abbiamo parlato noto come “effetto ELIZA”, attribuire sentimenti e idee umane a ciò che umano non è.
I modelli linguistici lavorano secondo un modello statistico, elaborando grandi quantità di dati sulla base di regole statistiche dedotte da una pletora di testi prodotti da esseri umani, secondo i parametri della perplessità e della rapidità.
L’esempio è la frase “Potresti offrirmi una tazza di…?”. Statisticamente parlando, le frasi più comuni sono “Una tazza di caffé”, “una tazza di the”, ma è improbabile un testo possa mai contenere “Una tazza di ragni” o “una tazza di petrolio greggio”, e quindi avrà un indice di perplessità elevato. Quindi l’indice di perplessità porterà alla classificazione come contenuto originale.

La Bibbia secondo ChatGPT
Altro concetto è la rapidità: in inglese burst. Leggete questo stesso testo: in alcuni punti vengono usate frasi più lunghe, in altre più corte. Alcune strutture sintattiche si ripetono: un bravo scrittore cerca sempre di non avere periodi di testo troppo lunghi, per evitare l’effetto “rantolo di Nonno Simpson”, il noto personaggio della serie americana che racconta storie includenti con capoversi che comincino da un evento e finiscono da tutt’altra parte.
Uno scrittore umano sa però quando dare eccezione alle sue stesse regole: un LLM cercherà di mantenere consistenza.
Passiamo ora a testi di elevata tecnicità come le Costituzioni e la Bibbia.
Essi appaiono direttamente citati in diversi testi, hanno una perplessità minima, e sono scritti volutamente per avere un ritmo costante, ieratico, sacrale.
Un LLM non ha mezzi per “capire il sacro e il profano”: vede semplicemente qualcosa che statisticamente potrebbe aver scritto lui perché basato su materiale in banca dati e su regole codificate da essi.
E il fact checking?
Abbiamo recentemente visto il caso di un utente spunta blu che ha cercato di sostituirci chiedendo a Gemini AI il fact checking di una notizia e vantandosi di aver scoperto una fake news.
Che però non lo era: era un falso positivo. La AI in Google aveva confuso due soggetti completamente diversi e interpolando dati stastistici in modo erroneo inferito di aver snidato una fake news.
Un fact checker per definizione è in grado di effettuare una analisi OSINT: cercherà tra tutte le fonti aperte, e talora chiedendo direttamente fonti chiuse agli interessati, ogni dato possibile.
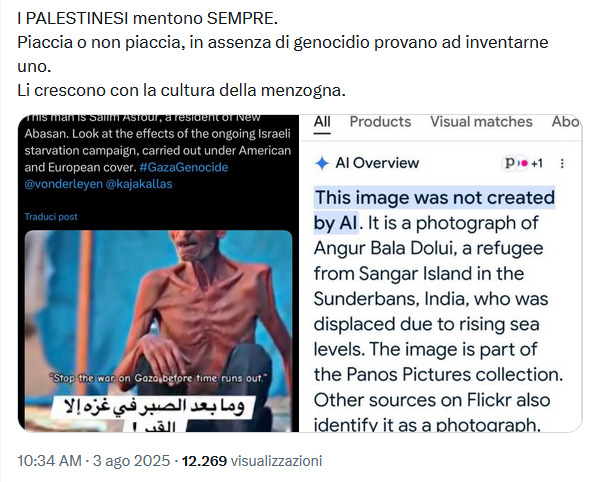
E invece mentiva la AI
Un modello di IA cercherà di accroccare qualcosa coi dati che ha, come il ragazzino svogliato che, colto impreparato, piuttosto che fare scena muta costruisce un modello di risposta coi dati che ha.
E talvolta ci prende, ma talvolta no.
Abbiamo già visto in passato i rischi della troppa fiducia nei “modelli di analisi e fact checking AI”: una studentessa laureanda in Scienze Politiche accusata di plagio da uno zelante corpo docente armato di AI Detector e dimostratasi innocente, un professore di Economia e Commercio Texano pronto a negare la laurea ad un intero gruppo di suoi studenti perché ChatGPT gli aveva suggerito fossero dei plagiatori e un professore accusato di violenze sessuali dalla stampa locale perché un aspirante “Debunker da ChatGPT” aveva ottenuto dall’AI gli estremi di falsi articoli sui suoi crimini sessuali.
Verità statistica non è verità dei fatti.
Abilità letteraria non è abilità statistica: al momento, la Costituzione resta ai costituenti e il fact checking ai fact checkers.
Se il nostro servizio ti piace sostienici su PATREON o
con una donazione PAYPAL.




